

Breaking down Speculative RAG
Breaking down Speculative RAG
Great work is many good works.

Keywords: LMs, RAG, multi-agent, divide-and-conquer.
Introduction
Recently, LLMs have become indispensable tools for enhancing performance in both work and school. With just a few clicks on our smartphones, we can access perfectly tailored information that reflects our unique perspectives. Thanks to their training on massive datasets, LLMs are capable of generating highly relevant and informative responses to user queries. However, over-reliance on these datasets can also be a double-edged sword. The data used to train LLMs is often outdated and can introduce biases or errors into the reasoning process. Additionally, the multifaceted nature of human language can lead to misunderstandings and inaccuracies in the generated content.
Retrieval-Augmented Generation (RAG) offers a promising solution to these challenges. By retrieving relevant information from external sources and feeding it into the LLM, RAG ensures that the generated responses are grounded in factual evidence and avoid hallucinations. This approach not only facilitates easy access to vast databases but also enables timely and accurate knowledge integration. However, RAG also faces limitations. The increased input length resulting from feeding external information into the LLM can lead to increased latency and require more complex reasoning processes.
Speculative RAG, which is a RAG framework, wants to end this problem by designing a method to offload computational burden to a smaller, specialist LM that serves as an efficient and robust RAG module for existing generalist LMs. In this blog, we will investigate the SpeculativeRAG (how it works, why it matters, and what it is). The roadmap for this writing is as follows:
A Brief Summary: I will mention related works that Speculative RAG were inspired. In addition, I would talk a little bit about how it works and its performances.
Going into Details: I discuss deeper about the framework by analyzing its components.
Experiment Results: I discuss some of its best results.
Conclusion: I will summarize that we have achieved to reach this stage. In addition, I want to give some thoughts about the framework.
Let’s dive in!
A Brief Summary
Motivation
Speculative RAG’s authors are motivated by overcoming the issues that RAG is facing and inspired by the speculative decoding. There are 3 main reasons that previous RAG frameworks are bad ideas, those are:
Resource-Intensive Fine-Tuning: Approaches like SAIL [3] and Self-Reflective RAG [4] require additional instruction-tuning of generic LLMs, which can be computationally expensive and time-consuming. This can limit their scalability and accessibility.
Long Context Limitations: Incorporating retrieved documents into the generation process can lead to long contexts, which can suffer from computational inefficiency and position bias. This means that the model may struggle to process all the information effectively and may prioritize information at the beginning of the context over later information.
Limited Reasoning Capabilities: Some approaches, like Corrective RAG [3], focus on evaluating the retrieved documents but lack the ability for high-level reasoning. This can limit their effectiveness in complex tasks that require understanding and integrating information from multiple sources.
The goal of speculative decoding is to reduce auto-regressive decoding delay using a draft-then-verify approach. This entails creating several future tokens using a small model and checking them simultaneously with the target model. Speculative RAG uses language modeling and aims to directly assess the confidence in full answer drafts.
Speculative RAG overview
Speculative RAG’s approach is designed to improve the efficiency and accuracy of answer generation. The framework divides retrieved documents into smaller groups based on their content similarity. This helps Speculative RAG focus on the most relevant information and avoid redundancy. From each group, it selects one representative document to use in creating draft answers and explanations.
Note: Keep in mind that SpeculativeRAG is a framework, which means that somewhere in its code-base must meet the Modularity: the ability to break down complex systems into smaller, manageable components, making it easier to develop, test, and maintain individual parts.
By working on both the answers and explanations simultaneously, Speculative RAG can ensure that the responses are not only accurate but also well-supported. This is particularly helpful because it allows the generalist LM to avoid wasting time on repetitive information. Instead, it can focus on validating the draft answers against their corresponding explanations.

Here's how it breaks down:
Divide and Conquer: Instead of giving all the articles to the AI at once, SPECULATIVE RAG groups similar articles together. Think of it like sorting your mail into piles by sender—it's much easier to handle!
Specialized Teams: Each group of similar articles is then given to a smaller, specialized AI that's really good at finding answers within a specific topic.
Parallel Processing: These specialized AIs work in parallel, like a team of experts tackling different parts of a puzzle, finding the best answers and explaining their reasoning.
Expert Review: Finally, a powerful generalist AI checks the answers from the specialized AIs and chooses the most accurate one.
In short, Speculative RAG uses a team of specialized AIs to find the best answers quickly and efficiently. It's like having a whole team of researchers working together to find the perfect solution for your query!
Going into Details
Concept
Remind ourselves that the objective of a RAG system is to generate a fluent response containing the expected answer or select the expected answer from the provided options based on the context provided by the retrieved supporting documents.
Speculative RAG reminds me one of philosophies of Unix, which is “Do one thing and do it well”, each program should have a single, well-defined purpose and execute it efficiently. This approach allows for simplicity, reliability, and maintainability.
Speculative RAG proposes a divide-and-conquer approach. It uses a smaller specialist LM, the RAG drafter, to rapidly generate multiple answer drafts based on retrieved results. After that, a larger generalist LM, the RAG verifier, evaluates these drafts, chooses the best one based on its logic, and incorporates it into the generating outcomes.

In knowledge intensive tasks, each entry can be represented as (Q, D, A), where Q is a question or statement that requires additional knowledge; D = {d1, ..., dn} is a set of n documents retrieved from the database; and A is the expected answer.
The framework’s initial step is a question step and n-retrieved documents and returns a predicted answer to the question, A^. The algorithm runs as follows:
Line 2: Using an embedding model C, the framework clusters the retrieved documents into k groups/clusters.
Line 3-10:
Line 3: Create a holder for diversity (each delta in this represents diverse contents and multiple perspectives in the retrieval results).
Line 4-9:
The algorithm samples one document from each cluster into a subset so the documents in this subset covers the multiple perspectives in the retrieval results → aim at minimizing redundancy and increase the diversity of the documents.
The diversity holder is updated by adding delta.
Repeat the sampling until there are m unique subsets.
Line 11-14:
Every deltas in the diversity holder to a RAG drafter and being processed in parallel. A set of the answer draft, alpha, and the rationale, beta, is generated for each delta.
Each set of the answer draft and the rational are then sent to the generalist LM to compute the confidence score. The score is in reference to the question Q and the rationale.
Line 15: Select the answer draft with the highest confidence score as the final answer and integrate it into the generation results of the generalist LM.
Specialist RAG Drafter
Instead of training a large, all-purpose language model to tackle a wide range of questions, the framework leverages a smaller, specialized language model called MDrafter. MDrafter is designed to focus on answering specific questions based on relevant documents, rather than trying to tackle complex problems on its own. It serves as a supporting tool for more general-purpose language models when working on tasks that require in-depth knowledge.

The framework trains MDrafter to generate not only the answer to a question but also the reasoning behind it, allowing for a deeper understanding of the context and the documents being referenced. This approach enables the framework to provide more accurate and informative responses to complex questions.
Instruction Tuning: Addition to each entry in the knowledge intensive task that I mentioned above is the rational E, which is of shorter length and delivers information relevant to the original document, we have a quadruple (Q, A, D, E). A pre-trained language model is fine-tuned with the standard LM objective: maximize this likelihood

On the log is the probability of generating the response and rationale based on the query and document. Using the instruction-tuned LM, the MDrafter is able to generate a well-grounded response and rationale given the query and relevant documents.
Multi-Perspective Sampling: After retrieved relevant documents based on user’s query, those documents will be processed again to ensure the redundancy is minimized and the documents’ diversity is enhanced. The strategy is done by using an instruction-aware embedding model and the K-Means clustering algorithms (the process is relevant to lines 3–10 in the algorithm that have been discussed above).

RAG Drafting: Each cluster/subset will be then fed into the MDrafter to pose a set of the answer draft and the rationale. The reliability of generating rationales and the confidence in producing answer drafts is measured as:

Generalist RAG Verifier
To achieve the best answer, Speculative RAG presents MVerifier, which is the generalist LM, to evaluate the answer drafts and the rationales by filtering out low quality draft. MVerifier can be off-the-shelf pre-trained LM.

Evaluation Scores: The generalist LM emphasizes the consistency and the reflection of the pair of the answer draft and the rationale, allows itself to assess the quality of the draft-rationale pair and make a more informed decision.
Self-Consistency Score: This score measures how well the draft and rationale match the question. It's like checking if the answer and explanation make sense together.
Self-Reflection Score: This score checks if the answer is reliable by asking a question like "Does the explanation support the answer?" The framework calculates the probability of getting a positive answer to this question.
Think of it like a two-step process:
Does the answer and explanation go together well? (Self-Consistency Score)
Does the explanation actually support the answer? (Self-Reflection Score)
Computation Method: To calculate the self-consistency and self-reflection scores, the framework uses a single pass through the model MVerifier.

It does this by:
Creating a prompt that includes the question, the draft, the rationale, the self-reflection statement, and the answer "Yes”, a quintuple of [Q, the answer draft, the rationale, the self-reflection statement, “Yes”].
Encoding this prompt with MVerifier, which generates a probability for each token in the prompt based on the previous tokens.
Using this probability to calculate the self-consistency score (how well the answer and explanation match the question) and the self-reflection score (whether the explanation supports the answer).
Combining these scores with the draft score to produce a final score for each answer.
Selecting the answer with the highest final score as the most reliable answer.
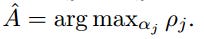
where


Experiment Results
The results demonstrate the superior performance of Speculative RAG over standard RAG approaches, Self-Reflective RAG, and Corrective RAG across four datasets: TriviaQA, MuSiQue, PubHealth, and ARC-Challenge. The combination of instruction-tuned RAG drafter and verifier models leads to significant improvements in accuracy, showcasing the effectiveness of the Speculative RAG approach.

Key results include:
Speculative RAG (MVerifier-8x7B + MDrafter-7B) outperforms the most competitive standard RAG model (Mixtral-Instruct8x7B) by 0.33% on TriviaQA, 2.15% on MuSiQue, 12.97% on PubHealth, and 2.14% on ARC-Challenge.
Instruction-tuned RAG drafter (MDrafter-7B) surpasses Self-Reflective and Corrective RAG methods in most settings.
Pairing Mixtral8x7B with MDrafter-7B leads to significant improvements of 14.39% on TriviaQA, 12.41% on MuSiQue, 39.52% on PubHealth, and 31.83% on ARC-Challenge.
The RAG verifier (MVerifier-7B) contributes to enhanced performance, with improvements of 19.76% on TriviaQA, 14.32% on MuSiQue, 40.94% on PubHealth, and 33.44% on ARC-Challenge when paired with MDrafter-7B.
By utilizing a smaller RAG drafter and parallel draft generation, Speculative RAG consistently achieves the lowest latency, highlighting its advantage in reducing processing time while maintaining high performance.

Key results include:
Speculative RAG (MVerifier-8x7B + MDrafter-7B) reduces latency by up to 23.41% on TriviaQA, 17.28% on MuSiQue, 51.25% on PubHealth, and 26.73% on ARC-Challenge compared to Standard RAG (Mixtral-Instruct8x7B).
Increasing tensor parallelism for Mixtral-Instruct8x7B does not improve efficiency due to overheads in tensor aggregation and communication.
Speculative RAG achieves the lowest latency across all datasets, demonstrating its advantage in reducing processing time while maintaining high performance.
The use of parallel draft generation with 5–10 endpoints of MDrafter-7B contributes to the reduced latency of Speculative RAG.
Additionally, the study also shows that:
Diversity and reduced redundancy in retrieval improve draft quality significantly.
The scoring method on self-consistency and self-reflection refines draft quality effectively.
The rationale highlights relevant points, omits redundant information, and bridges logical gaps between drafts and their supporting documents. This leads to accurate final results, highlighting the importance of the generated rationale in the speculative RAG approach.
The more the merrier: the more drafts that we allow the specialist to do can further improve performance.
Conclusion
In this blog, our journey began with understanding the motivation of Speculative RAG by reviewing the advantages and disadvantages of LLMs and previous RAG frameworks. We looked and dived deeply into the architectures of Speculative RAG by analyzing the algorithm and components of the framework. We viewed some of its benchmarks in TriviaQA, MuSiQue, PubHealth, ARC-C.
Speculative RAG represents a significant breakthrough in AI technology, offering a more efficient and effective approach to generating high-quality answers. By breaking down the process into drafting and verification and leveraging the strengths of both specialized and generalist language models, Speculative RAG achieves substantial improvements in both speed and quality.
I think that this approach has the potential to change the way we interact with AI, making it more accessible and reliable for everyone. As AI continues to evolve, Speculative RAG is an exciting development that holds great promise for the future of language generation and understanding.
Thank you for reading this article; I hope it added something to your knowledge bank! Just before you leave:
👉 Be sure to clap and follow me. It would be a great motivation for me.
👉Follow me: LinkedIn | Github | Substack
Reference
Wang et al. - Speculative RAG: Enhancing retrieval augmented generation through drafting - URL: https://arxiv.org/html/2407.08223v1
Wang et al. - Speculative RAG: Enhancing retrieval augmented generation through drafting (Blog) - URL: https://research.google/blog/speculative-rag-enhancing-retrieval-augmented-generation-through-drafting/#:~:text=Speculative RAG is a novel,both in accuracy and efficiency
Luo et al. - SAIL: Search-Augmented Instruction Learning - URL: https://arxiv.org/abs/2305.15225
Asai et al. - Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection - URL: https://arxiv.org/abs/2310.11511
Yan et al. - Corrective Retrieval Augmented Generation - URL: https://arxiv.org/abs/2401.15884
Appendix
Personal thought: I think one of the key notes in this process is the MDrafter does drafting in parallel. It brings a trade-off between speeding up the process, improving productivity, and the cost and complexity of parallel computing.